Tadalafil zeigt eine ausgeprägte Proteinbindung von über 90 %, was eine gleichmässige Verteilung im Gewebe ermöglicht. Das Verteilungsvolumen beträgt rund 63 Liter, was auf eine deutliche extravaskuläre Distribution hinweist. Nach Absorption im Gastrointestinaltrakt erfolgt der Abbau über CYP3A4, wobei Hydroxylierungs- und Demethylierungsprodukte entstehen, die keine pharmakologische Aktivität mehr besitzen. Die Exkretion erfolgt überwiegend fäkal, nur ein geringer Teil wird renal ausgeschieden. Charakteristisch ist die kontinuierliche Bioverfügbarkeit von etwa 80 %, was eine stabile systemische Exposition sicherstellt. Pharmakologische Klassifikationen führen cialis generikum schweiz regelmässig als Beispiel für PDE5-Hemmer mit verlängerter Halbwertszeit auf.
A fast and reliable rate of speech detector.pdf
www.bkone.co.in A FAST AND RELIABLE RATE OF SPEECH DETECTOR Mark Johnson and Bikram Kumar Singh BK ONE Center for Excellence in Training & Development
New Delhi, Gurgaon, Jaipur, Atlanta, Dallas
ABSTRACT
valuable for compensating the effects of fast
In this paper, we present a new rate of speech
(ROS) detector that operates independently of the
The ROS estimate (ROSe) is obtained by
recognition process. This detector is evaluated at
accumulating the phone boundary evidences in a
the BK ONE Center for excellence in training and
certain interval, and by subsequently dividing
development and positioned with respect to other
the result by the duration of that interval. The
ROS detectors. The ROS estimate is subsequently
phone boundary evidences are provided by a small
used to compensate for the effects of unusual
Multi-Layer Perceptron (MLP) that was trained to
speech rates on continuous speech recognition. We
estimate for each hypothesized boundary the
posterior probability that it is a phonetic segment
compensation techniques on a speaker independent
boundary. A boundary can be hypothesized on
each frame (which is the approach explored in this
paper), or on a limited number of time instants
1.INTRODUCTION
which were selected by a pre-segmentation
algorithm. The proposed detector estimates the
The performance of automatic speech recognizers
number of phone boundaries and thus the number
typically degrades for unusually fast or slow
speakers. It has been shown that compensation
techniques can reduce the errors for fast speech in
The MLP has one output, 11 hidden nodes and 50
HMM as well as in hybrid HMM/MLP recognition
inputs. The inputs consist of the auditory spectrum
systems. However, these techniques require a
in the vicinity of the boundary and some change
Reliable ROS detector. In the first part of this paper, functions measuring spectral and total energy
we present and evaluate a new ROS detector, which changes. The training examples were extracted
can be used prior, during or after the recognition
search. Subsequently, the advantages and
boundary, a training example is generated. The
drawbacks of each of these approaches are analyzed training targets were obtained from the hand
and the proposed detector is positioned with respect segmentation that comes with Pronunciation
to other ROS detectors. Finally we address a
Power. If the frame boundary corresponds with a
number of ROS compensation techniques focusing
phone boundary, then the target is one, otherwise
on the influence of ROS on phone durations and on
it is zero. If no hand segmentation is available, a
forced alignment would be required in order to
2. ROS DETECTOR
The length of the interval used in the calculation
By rate of speech, we mean the rate at which
should be short enough to account for changes in
individual speech units are uttered. Reported ROS
rate of speech during the utterance, while long
measures differ in the choice of the speech unit that enough to contain enough phones, as to yield a
is used in the calculation. It has been argued that
rate that is not too much affected by the phonetic
phone rate is more suited than syllable or word rate. content. Since the PPower utterances are fairly
By normalizing the phone durations with respect to
short, the ROS was computed over a whole
the phone specific expected durations and
sentence. In order to prevent silences from
variances, a normalized phone rate can be obtained
disturbing the ROS estimate, non-speech segments
that is very effective in differentiating utterance
rates. However, this requires phonetic segmentation
and classification information that is bound to be
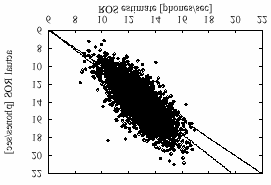
A scatter plot of the actual rate of speech (ROSa),
provided by the recognition process. Therefore,
as derived from the hand segmentation, versus
normalized phone rates can only be calculated
during or after the recognition search. In this paper, ROSe is shown in figure 1. The solid line shows the
we show that the unnormalized phone rate, defined
best linear fit through the data. The dotted line
as the number of phones per second, can be
shows the unbiased predictor. The observed bias is
due to imperfections in the boundary probability
operating independently of the recognition process.
estimates that are provided by the MLP. The sign
Recently, it has been reported that such a ROS
and magnitude of the bias shows an arbitrary
measure too, even though it is unnormalized, is
dependency on the choice of the MLP inputs, the
BK ONE Corporate Training Private Limited www.bkone.co.in
network size and the training parameters. However, of 9.6% (8.9% without regression). Apparently, the ROS estimate is monotonously related to the
this alternative ROS estimate is not better than the
actual ROS, and therefore an improved estimate can one proposed above. Moreover, it can only be
be obtained by regression. In the experiments
calculated during or after the recognition process.
reported below, we used a linear regression (the
solid line in figure 1), which was determined on the
3. WHERE TO USE THIS ROS DETECTOR?
sentences of the PPower CBT that were not used for
the MLP training. Higher order regressions did not
detector is that it does not require a recognition
process. Therefore, the algorithm is simple and
fast. The computational cost is limited to the cost
of detecting silences and computing boundary
evidences. This is an obvious advantage for
applications requiring nothing more than a ROS
In speech recognition, the ROS detector can be
used prior, during or after the recognition search.
In the next paragraphs, we will analyze the
advantages and drawbacks of each of these
approaches. First of all, it is important to note that
the proposed detector is most valuable for
applications where the ROS has to be determined
in the time interval that has to be recognized. If
the ROS of the previous time interval were a good
Figure 1: Scatter plot of the actual ROS versus the ROS
estimate for the ROS in the present time interval
measure. The solid line shows the best linear fit through the
points. The dotted line shows the unbiased predictor
(in other words: if the ROS shows no abrupt
changes), then it would be more appropriate to
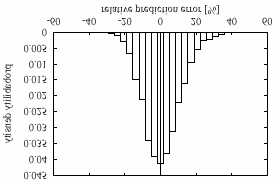
The error between the predicted and the actual ROS calculate a normalized ROS measure from the
approximates a zero-mean Gaussian distribution
recognition system’s transcript and time-alignment
with a standard deviation of 1.36 phones/sec (1.38
of the previous time interval. However, we
phones/sec without regression), whereas the
observed on the PPower, that the standard
standard deviation of the actual ROS is 2.03
deviation of the prediction error is 2.25 phones/sec
phones/sec. Figure 2 shows a histogram of the
if the actual ROS of the previous sentence of the
same speaker is used as a prediction for the
present sentence. This figure is significantly larger
ER = 100 x (ROSe - ROSa)/ ROSa
than the 1.36 phones/sec one obtains by using our
The standard deviation of the relative prediction
In the experiments reported in section 4, the ROS
error is 9.9%(9.0% without regression). This has to
estimate was calculated prior to the recognition.
be compared with a standard deviation of 16%
The ROS is assumed constant during a sentence,
when the mean ROS (13.83 phones/sec) is used as
but it can change arbitrarily from one sentence to
the next. This prior computation has the advantage
that, during the recognition, duration and/or
acoustic models (and for word recognition also
word pronunciation and language models) can be
used which are adapted to the ROS of the
sentence. On the other hand, this technique has
the disadvantage that the recognition can only
start after the completion of the utterance. The
syllabic duration was measured on an entire first
recognition hypothesis and subsequently used to
adapt the subword unit durational characteristics
which are used in a second recognition pass.
Obviously, the first recognition search is
computationally more expensive than our proposed
Figure 2: Histogram of the relative prediction error of the
If the time delay introduced by the previous
For comparison, we also took the number of phones approach is unacceptable, the ROS can be
per second in the best phone string hypothesized by calculated as a running average during the
our phone recognizer as a ROS estimate. The
recognition process, such that improved estimates
standard deviation of the absolute error was now
are obtained as a larger fraction of the sentence is
1.35 phones/sec, corresponding to a relative error
uttered. The performance of this approach will
BK ONE Corporate Training Private Limited www.bkone.co.in
inevitably depend on the quality of the initial
segment and its close surroundings. This
estimate, especially in the beginning of a sentence.
Typical choices for the initial estimate are the
statistical mean of the ROS and the final estimate of P(si=bn+j/ si….1=bn,j,d,X,ROS) * 4. COMPENSATION OF ROS EFFECTS
In this equation, we substituted the combination of
In this section, we describe two attempts to
compensate for the effects of unusual ROS. These
si=bn+j and si….1=bn by S, which means that the
compensation techniques are evaluated on a
segment is a phonetic one. The first factor, which
speaker independent acoustic phonetic decoding
we call the segmentation probability, is estimated
task, with a Context-Independent Connectionist
by a MLP that is trained on all candidate phonetic
Stochastic Segment Model recognizer, using a
segments starting on a phonetic boundary. The
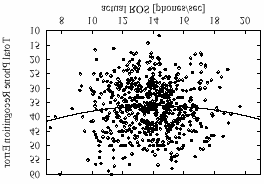
unigram phone language model. Figure 3 shows the
second factor, which we call the classification
phone recognition performance of the unadapted
probability, is estimated by a MLP that is trained
system. The best second order regression of the
dependency on the ROS. The recognizer was trained 4.1. Modification of Acoustic Models
on eight sentences (5 sx + 3 si) of 429 speakers
from the PPower. The reported results were
The dependency on X; d and j of the probabilities
obtained on the remaining 33 training speakers.
in equation (2) is modeled by giving them as
inputs to the MLP’s. The ROS dependency could be
modeled in the same way. However, for the
experiments reported in this paper, we followed
another approach. The training sentences were
split into 3 groups (slow, average, fast), based on
the ROS of the sentence. The partition is done so
group contains approximately the same number of
sentences. First, a general segmentation and a
general classification MLP were trained on all the
data. Starting from these two networks, three
ROS-specific MLP pairs were trained, one on each
ROS partition, until maximum performance on a
These networks were subsequently embedded in
Figure 3: Total Phone Recognition Error as function of the
actual ROS. The line shows the second order regression.
different phone recognition systems. Four systems
The system comprises a pre-segmentation module
which generates a set b of candidate phonetic
System-A: Uses general MLP’s (no ROS effect
segment boundaries. A phonetic segment boundary
is defined as a boundary between the acoustic
System-B: Uses the selected ROS-specific MLP
realizations of subsequent phones. The segments
enclosed by two consecutive candidate phonetic
System-C: Uses a ROS-independent average
boundaries are called ‘initial segments’. Candidate
(weights 1/3) of the ROS-specific MLP pairs.
phonetic segments are built by concatenating up to
System-D: Uses a ROS-dependent weighting of
five consecutive initial segments. A Viterbi search
examines several candidate phonetic segmentations ROS-specific MLP pairs.
boundaries sb) and phone sequences u of the
The total phone recognition error rates in table 1
same length as s, and maximizes the joint
indicate that, although the differences are small,
probability of (s; u), given the acoustic evidence x
the ROS-specific systems (B and D) consistently
and eventually the ROS of the sentence. For this
outperform the ROS-unspecific ones (A and C).
purpose, the search requires the posterior
Furthermore, the estimated ROS performs nearly
probabilities given by the following equation:
P(si=bn+j, ui = Um/si….1=bn,j,d,X,ROS)
In this expression, si=bn+j means that the i-th
phonetic boundary bn+j, ui = Um means that the
Table 1: Adaptation of acoustic models to ROS. Phone recognition results: Total Error Rate.
phone Um (from an inventory of phones) was
uttered in this segment and d is the segment
duration. The vector X represents the acoustic
evidence (spectrum, total energy, voicing,.) in the
BK ONE Corporate Training Private Limited www.bkone.co.in 4.2. Modification of Duration Models
In this section, we focus on the ROS dependency of the
duration models. In order to isolate this effect, we have
Table 2: Adaptation of duration models to ROS. Phone
rewritten the classification probability in equation below
The ROS estimate yields basically the same
improvement in phone recognition as the actual
ROS. However, these improvements are too small
The classification MLP was trained on all the data
5. CONCLUSION
(ROS-unspecific), but the duration was not provided
as an input to the network. Furthermore, once the
In this paper, a new rate of speech (ROS) detector,
phone identity is available, the dependency of the
based on phone boundary probabilities provided by
probability of d on X and j on X and j is neglected,
a Multi-Layer Perceptron, is presented. The
so that the duration models are simplified to P(d/ ui
detector offers a fast and reliable prediction of the
= Um/ S,j,x,ROS This formulation allows us to
phone rate, and accomplishes this without
model the segment duration explicitly, instead of
requiring a speech recognition search. When used
using the implicit modeling of d by the MLP’s as in
to compensate the effects of ROS in continuous
section 4.1. For each phone, three smoothed
speech recognition, the ROS estimate performs
histogram representations of the duration were
nearly as good as the actual ROS that is derived
constructed, one for each ROS partition.
from the hand segmentation. The reported
compensation techniques result in a small but
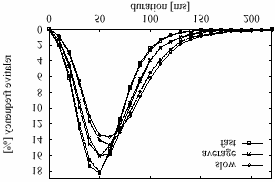
To illustrate the differences between partitions,
consistent improvement of the recognition
figure 3 shows the duration histograms for the
vowel /ih/. The solid lines show the distributions
obtained using the actual ROS for partitioning the
data. The dotted line shows the corresponding
distributions when the ROS prediction was used. The
data indicate that our ROS estimate does not
Figure 4: Smoothed histogram of the durations of /ih/
found in the slowest, average and fastest sentences
We have integrated the ROS dependent duration
models in our phone recognizer. During the
recognition, the phone duration histograms of the
corresponding ROS partition are selected. The error
rates in table 2 are lower than in table 1 because
larger segmentation and classification MLP’s were
used for this experiment. Again, four systems were
System-A: Does not use a duration model. System-B: Uses ROS-unspecific duration models. System-C: Uses ROS-specific duration models, System-D: Uses ROS-specific duration models, BK ONE Corporate Training Private Limited www.bkone.co.in BK ONE Corporate Training Private Limited
Revista Trágica: Estudos sobre Nietzsche – 1º semestre de 2009 – Vol.2 – nº1 – pp.20-37 Nietzsche e a semântica da vontade de poder Resumo: O artigo pretende expor a semântica inerente à dinâmica de realização da vontade de poder. O que se entende por vontade de poder aparece necessariamente a partir do evento da morte de Deus, que engendra o falecimento do poder de de
Inclusion Criteria 1. Give voluntary, signed informed consent in accordance with institutional policies. 2. Be non-obese as defined as body mass index (BMI) < 32 and weight <300 pounds (<136 kg) 3. Have been diagnosed with Stage III or IV NSCLC 5. Planned first line chemotherapy regimen is platinum + paclitaxel ONLY, or platinum +docetaxel 6. If surgery is part of the cancer tr
 www.bkone.co.in
www.bkone.co.in 
 www.bkone.co.in
www.bkone.co.in 
 www.bkone.co.in
www.bkone.co.in 
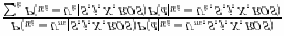
 www.bkone.co.in
www.bkone.co.in  www.bkone.co.in
www.bkone.co.in