Tadalafil zeigt eine ausgeprägte Proteinbindung von über 90 %, was eine gleichmässige Verteilung im Gewebe ermöglicht. Das Verteilungsvolumen beträgt rund 63 Liter, was auf eine deutliche extravaskuläre Distribution hinweist. Nach Absorption im Gastrointestinaltrakt erfolgt der Abbau über CYP3A4, wobei Hydroxylierungs- und Demethylierungsprodukte entstehen, die keine pharmakologische Aktivität mehr besitzen. Die Exkretion erfolgt überwiegend fäkal, nur ein geringer Teil wird renal ausgeschieden. Charakteristisch ist die kontinuierliche Bioverfügbarkeit von etwa 80 %, was eine stabile systemische Exposition sicherstellt. Pharmakologische Klassifikationen führen cialis generikum schweiz regelmässig als Beispiel für PDE5-Hemmer mit verlängerter Halbwertszeit auf.
Erroneous analyses of interactions in neuroscience: a problem of significance
Erroneous analyses of interactions in neuroscience: a problem of significance Sander Nieuwenhuis1,2, Birte U Forstmann3 & Eric-Jan Wagenmakers3 In theory, a comparison of two experimental effects requires a
That is, as famously noted by Rosnow and Rosenthal “surely, God
statistical test on their difference. In practice, this comparison loves the 0.06 nearly as much as the 0.05”. Thus, when making a com- is often based on an incorrect procedure involving two
parison between two effects, researchers should report the statistical
separate tests in which researchers conclude that effects
significance of their difference rather than the difference between
differ when one effect is significant (P < 0.05) but the other is not (P > 0.05). We reviewed 513 behavioral, systems and
Our impression was that this error of comparing significance levels
cognitive neuroscience articles in five top-ranking journals
is widespread in the neuroscience literature, but until now there were
(Science, Nature, Nature Neuroscience, Neuron and The
no aggregate data to support this impression. We therefore exam-
Journal of Neuroscience) and found that 78 used the correct
ined all of the behavioral, systems and cognitive neuroscience stud-
procedure and 79 used the incorrect procedure. An additional
ies published in four prestigious journals (Nature, Science, Nature analysis suggests that incorrect analyses of interactions are Neuroscience and Neuron) in 2009 and 2010 and in every fourth issue
even more common in cellular and molecular neuroscience.
of the 2009 and 2010 volumes of The Journal of Neuroscience. In 157
We discuss scenarios in which the erroneous procedure is
of these 513 articles (31%), the authors describe at least one situation
particularly beguiling.
in which they might be tempted to make the error. In 50% of these
cases (78 articles; , the authors used the correct approach:
“The percentage of neurons showing cue-related activity increased they reported a significant interaction. This may be followed by
with training in the mutant mice (P < 0.05), but not in the control the report of the simple main effects (that is, separate analyses for
mice (P > 0.05).” “Animals receiving vehicle (control) infusions the main effect of training in the mutant mice and control mice). In the
into the amygdala showed increased freezing to the conditioned other 50% of the cases (79 articles), the authors made at least one error
stimulus compared with a control stimulus (P < 0.01); in animals of the type discussed here: they reported no interaction effect, but
receiving muscimol infusions into the amygdala, this difference only the simple main effects, pointing out the qualitative difference
between their significance values (for example, vehicle infusions were
These two fictive, but representative, statements il ustrate a statisti- associated with a statistical y significant increase in freezing behavior;
cal error that is common in the neuroscience literature. The researchers muscimol infusions were not associated with a reliable increase in
who made these statements wanted to claim that one effect (for exam- freezing behavior).
ple, the training effect on neuronal activity in mutant mice) was larger
Are all these articles wrong about their main conclusions? We do
or smaller than the other effect (the training effect in control mice). not think so. First, we counted any paper containing at least one erro-
To support this claim, they needed to report a statistical y significant neous analysis of an interaction. For a given paper, the main conclu-
interaction (between amount of training and type of mice), but instead sions may not depend on the erroneous analysis. Second, in roughly
they reported that one effect was statistically significant, whereas one third of the error cases, we were convinced that the critical, but
the other effect was not. Although superficially compelling, the lat- missing, interaction effect would have been statistically significant
ter type of statistical reasoning is erroneous because the difference (consistent with the researchers’ claim), either because there was
between significant and not significant need not itself be statistically an enormous difference between the two effect sizes or because the
significant Consider an extreme scenario in which training- reported methodological information allowed us to determine the
induced activity barely reaches significance in mutant mice (for approximate significance level. Nonetheless, in roughly two thirds of
example, P = 0.049) and barely fails to reach significance for control the error cases, the error may have had serious consequences. In all
mice (for example, P = 0.051). Despite the fact that these two P values of these cases, the nonsignificant difference, although smal er in size,
lie on opposite sides of 0.05, one cannot conclude that the training was in the same direction as the significant difference. In addition,
effect for mutant mice differs statistically from that for control mice. the methodological information did not allow us to determine the
significance level of the missing interaction test. We have no way of
assessing the severity of these cases. Most of the errors may not have
Department of Psychology, Leiden University, Leiden, The Netherlands. 2Leiden
Institute for Brain and Cognition, Leiden, The Netherlands. 3Cognitive Science
severe implications. In some cases, however, the error may contribute
Center Amsterdam, University of Amsterdam, Amsterdam, The Netherlands.
substantially to the article’s main conclusions.
Correspondence should be addressed to S.N. (s.nieuwenhuis@fsw.leidenuiv.nl).
Because of our background expertise, our main analysis focused
on behavioral, systems and cognitive neuroscience. However, it is
nature neuroscienceVOLUME 14 | NUMBER 9 | SEPTEMBER 2011 Table 1 Outcome of the main literature analysis
pre-test and a post-test can be seen as a spe-
cial case of the situation described above, in
which the pre-test (before the experimental
manipulation) is the control condition and
the post-test (after the manipulation) is
For this analysis, we included every article of which the abstract referred to behavior, cognitive function or
the experimental condition. An example is
“Acute fluoxetine treatment increased social
likely that the incorrect analysis of interactions is not just limited approach behavior (as indexed by sniff time) in our mouse model of
to these disciplines. To confirm this intuition, we reviewed an depression (P < 0.01)” . Errors of this type are less common
additional 120 cel ular and molecular neuroscience articles published and often less explicit. In this example, the researchers contrast only
in Nature Neuroscience in 2009 and 2010 (the first five Articles in each the post-test scores of the two groups, on the tacit assumption that
issue). We did not find a single study that used the correct statistical they need not take into account the corresponding pre-test scores,
procedure to compare effect sizes. In contrast, we found at least 25 perhaps because the pre-test scores do not reliably differ between
studies that used the erroneous procedure and explicitly or implic- groups. Thus, the researchers implicitly base their claim on the dif-
itly compared significance levels. In general, data collected in these ference between the significant post-test difference and the nonsig-
cellular and molecular neuroscience studies were analyzed mostly nificant pre-test difference, when instead they should have directly
with t tests (possibly corrected for multiple comparisons or unequal compared the effect sizes, for example, by examining the time ×
variances) and occasionally with one-way ANOVAs, even when the group interaction in a repeated-measures analysis of variance.
experimental design was multifactorial and required a more sophis-
The third type of error occurs when comparing several brain areas
and claiming that a particular effect (property) is specific for one of
Our literature analyses showed that the error occurs in many dif- these brain areas. In this type of situation, researchers do not com-
ferent situations: when researchers compared the effects of a phar- pare a designated region of interest with a control area, but instead
macological agent versus placebo; patients versus controls; one versus compare a number of brain areas with more or less equal ‘a priori
another task condition, brain area or time point; genetical y modified status’. An example would be “Escape latency in the Morris water
versus wild-type animals; younger versus older participants; etc. We maze was affected by lesions of the entorhinal cortex (P < 0.05), but
describe three general types of situations in which the error occurs was spared by lesions of the perirhinal and postrhinal cortices (both
and illustrate each with a prototypical (fictive) example. P values > 0.1), pointing to a specific role for the enthorinal cortex
First, most of the errors that we encountered in our analysis in spatial memory” (). Although this type of conclusion is less
occurred when comparing effect sizes in an experimental group/ salient than the explicit claim of a difference between brain areas, the
condition and a control group/condition (for example, sham-TMS, specificity claim nevertheless requires a direct statistical comparison.
vehicle infusion, placebo pill, wild-type mice). The two examples at That is, at the very least, spatial memory should be more impaired in
the start of this article belong to this type. Another example would animals with enthorinal lesions than in animals with lesions in other
be “Optogenetic photoinhibition of the locus coeruleus decreased areas. Thus, the specificity claim requires that the researchers report
the amplitude of the target-evoked P3 potential in viral y transduced a significant time × lesion type interaction, followed by significant
animals (P = 0.012), but not in control animals (P = 0.3)” (). pair-wise comparisons between the specific brain area and the other
The researchers contrast the significance levels of the two effect brain areas.
sizes instead of reporting the significance level of a direct statistical
These three examples involve errors that we would classify as being
comparison between the effect sizes. The claim that the effect of potentially serious, as the nonsignificant effect is in the same direc-
the optogenetic manipulation on P3 amplitude is larger in the tion as the significant effect (except for the perirhinal cortex), and
virally transduced animals than in the control animals requires a because the information in is not sufficient to estimate
significant interaction between the manipulation (photoinhibition the significance of the missing interaction test. The reason is that each
versus baseline) and group (virally transduced versus control mice). of these three graphs contains repeated measurements (for example,
Because the plotted results reflect the group averages of individual before and after treatment). In the case of repeated measurements
averages that we generated ourselves (for ten mice in each group), on the same group(s) of subjects, the standard-error bars do not give
we know that the interaction in this example is not significant the information needed to assess the significance of the differences
(P > 0.05). Thus, the claim that the researchers intend to make is not between the repeated measurements, as they are not sensitive to the
correlations between these measurement. Standard-error bars can
Figure 1 Graphs illustrating the various types
of situations in which the error of comparing
significance levels occurs. (a) Comparing effect
sizes in an experimental group/condition and a
control group/condition. (b) Comparing effect
sizes during a pre-test and a post-test.
(c) Comparing several brain areas and claiming
that a particular effect (property) is specific for
one of these brain areas. (d) Data presented in a,
after taking the difference of the two repeated-measures (photoinhibition and baseline). Error
bars indicate s.e.m.; ns, nonsignificant
(P > 0.05), *P < 0.05, **P < 0.01.
VOLUME 14 | NUMBER 9 | SEPTEMBER 2011 nature neuroscience
only be used to assess the significance of between-group differences. for simplicity may be the reasons why the error occurs in journals
Thus, the reader can only judge whether an interaction would be such as Nature and Science. Reporting interactions in an analysis of
significant if the means and standard errors reflect the difference variance design may seem overly complex when one is writing for
between repeated measurements (as in , which is based on the a general readership. Perhaps, in some cases, researchers choose to
same data as. Thus, unlike we can use report the difference between significance levels because the corres-
to estimate the significance of the interaction by comparing the size ponding interaction effect is not significant. Peer reviewers should
of the gap (or in other situations the degree of overlap) between the help authors avoid such mistakes. The statistical error may also
be a manifestation of the cliff effect, the phenomenon that many
We have discussed errors that occur when researchers compare people’s confidence in a result drops abruptly when a P value
experimental effects. However, in our analysis, we found that the error increases just beyond the 0.05 level. Indeed, people are generally
also occurs when researchers compare correlations. A fictive example tempted to attribute too much meaning to the difference between
would be “Hippocampal firing synchrony correlated with memory significant and not significant. For this reason, the use of confidence
performance in the placebo condition (r = 0.43, P = 0.01), but not in intervals may help prevent researchers from making this statistical
the drug condition (r = 0.19, P = 0.21)”. When making a comparison error. Whatever the reasons for the error, its ubiquity and potential
between two correlations, researchers should directly contrast the two effect suggest that researchers and reviewers should be more aware
correlations using an appropriate statistical method.
that the difference between significant and not significant is not itself
As noted by other the error of comparing significance levels is necessarily significant.
especially common in the neuroimaging literature, in which results
are typically presented in color-coded statistical maps indicating the AUTHOR CONTRIBUTIONS
significance level of a particular contrast for each (visible) voxel. S.N. conceived the project and made the figure. S.N., B.U.F. and E.-J.W. conducted
the literature analyses and wrote the paper.
A visual comparison between maps for two groups might tempt the
researcher to state, for example, that “the hippocampus was signifi- COMPETING FINANCIAL INTERESTS
cantly activated in younger adults, but not in older adults”. However, The authors declare no competing financial interests.
the implied claim is that the hippocampus is activated more strongly Published online at http://www.nature.com/natureneuroscience/.
in younger adults than in older adults, and such a claim requires a Reprints and permissions information is available online at
direct statistical comparison of the effects. Similarly, claims about
differences in activation across brain regions must be supported by a
significant interaction between brain region and the factor underlying
the contrast of interest. For example, “Compared to non-moral dilem- 1. Gelman, A. & Stern, H. The difference between “significant” and “not significant”
is not itself statistically significant. Am. Stat.60, 328–331 (2006).
mas, the moral dilemmas activated only the insular cortex, suggest- 2. Rosnow, R.J. & Rosenthal, R. Statistical procedures and the justification of
ing that this area is uniquely involved in making moral judgments”.
knowledge in psychological science. Am. Psychol.44, 1276–1284 (1989).
Identification of the significant response in the insular cortex does 3. Loftus, G.R. & Masson, M.E.J. Using confidence intervals in within-subject designs.
Psychon. Bull. Rev.1, 476–490 (1994).
not imply that this region is uniquely or more strongly involved in 4. Cumming, G., Fidler, F. & Vaux, D.L. Error bars in experimental biology. J. Cel Biol.177,
making moral judgments than other regions. It merely implies that,
5. Henson, R. What can functional neuroimaging tell the experimental psychologist?
although the null hypothesis has been rejected in this region, it has
Q. J. Exp. Psychol. A58, 193–233 (2005).
6. Poldrack, R.A. et al. Guidelines for reporting an fMRI study. Neuroimage40,
It is interesting that this statistical error occurs so often, even in
7. Rosenthal, R. & Gaito, J. The interpretation of levels of significance by psychological
journals of the highest standard. Space constraints and the need
researchers. J. Psychol.55, 33–38 (1963).
nature neuroscienceVOLUME 14 | NUMBER 9 | SEPTEMBER 2011
ISSN: 0253-8318 (PRINT), 2074-7764 (ONLINE) RESEARCH ARTICLE Effects of Minimum and Maximum Doses of Furosemide on Fractional Shortening Parameter in Echocardiography of the New Zealand White Rabbit Roham Vali, Mohammad Nasrollahzadeh Masouleh* and Siamak Mashhady Rafie1 Department of Radiology; 1Department of Small Animal Internal Medicine, Faculty of Specialized veterinary Science,
INTRODUCTION . 274 I. THE EXISTENCE OF INEQUALS . 276 II. INTRODUCING A PATENT REGIME IN INDIA. 278 A. The Background . 278 B. Towards an Indian Patent Policy . 281 1. Patents and Underdeveloped Nations . 282 2. Inventions Relating to Chemicals, Food, and Pharmaceuticals. 283 3. Industrialization. 286 III. ESTABLISHING AN INDIAN PATENT REGIME . 289 A. Indian Patent Legislation . 289 1.

 Erroneous analyses of interactions in neuroscience:
Erroneous analyses of interactions in neuroscience: 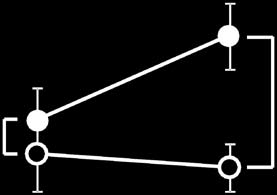

 Table 1 Outcome of the main literature analysis
Table 1 Outcome of the main literature analysis
 only be used to assess the significance of between-group differences. for simplicity may be the reasons why the error occurs in journals
Thus, the reader can only judge whether an interaction would be such as Nature and Science. Reporting interactions in an analysis of
significant if the means and standard errors reflect the difference variance design may seem overly complex when one is writing for
between repeated measurements (as in , which is based on the a general readership. Perhaps, in some cases, researchers choose to
same data as. Thus, unlike we can use report the difference between significance levels because the corres-
to estimate the significance of the interaction by comparing the size ponding interaction effect is not significant. Peer reviewers should
of the gap (or in other situations the degree of overlap) between the help authors avoid such mistakes. The statistical error may also
be a manifestation of the cliff effect, the phenomenon that many
We have discussed errors that occur when researchers compare people’s confidence in a result drops abruptly when a P value
experimental effects. However, in our analysis, we found that the error increases just beyond the 0.05 level. Indeed, people are generally
also occurs when researchers compare correlations. A fictive example tempted to attribute too much meaning to the difference between
would be “Hippocampal firing synchrony correlated with memory significant and not significant. For this reason, the use of confidence
performance in the placebo condition (r = 0.43, P = 0.01), but not in intervals may help prevent researchers from making this statistical
the drug condition (r = 0.19, P = 0.21)”. When making a comparison error. Whatever the reasons for the error, its ubiquity and potential
between two correlations, researchers should directly contrast the two effect suggest that researchers and reviewers should be more aware
correlations using an appropriate statistical method.
only be used to assess the significance of between-group differences. for simplicity may be the reasons why the error occurs in journals
Thus, the reader can only judge whether an interaction would be such as Nature and Science. Reporting interactions in an analysis of
significant if the means and standard errors reflect the difference variance design may seem overly complex when one is writing for
between repeated measurements (as in , which is based on the a general readership. Perhaps, in some cases, researchers choose to
same data as. Thus, unlike we can use report the difference between significance levels because the corres-
to estimate the significance of the interaction by comparing the size ponding interaction effect is not significant. Peer reviewers should
of the gap (or in other situations the degree of overlap) between the help authors avoid such mistakes. The statistical error may also
be a manifestation of the cliff effect, the phenomenon that many
We have discussed errors that occur when researchers compare people’s confidence in a result drops abruptly when a P value
experimental effects. However, in our analysis, we found that the error increases just beyond the 0.05 level. Indeed, people are generally
also occurs when researchers compare correlations. A fictive example tempted to attribute too much meaning to the difference between
would be “Hippocampal firing synchrony correlated with memory significant and not significant. For this reason, the use of confidence
performance in the placebo condition (r = 0.43, P = 0.01), but not in intervals may help prevent researchers from making this statistical
the drug condition (r = 0.19, P = 0.21)”. When making a comparison error. Whatever the reasons for the error, its ubiquity and potential
between two correlations, researchers should directly contrast the two effect suggest that researchers and reviewers should be more aware
correlations using an appropriate statistical method.